
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Ai
- wavenet
- Neural Collaborative Filtering
- Noise Contrastive Estimation
- 부스트캠프 AI Tech
- Tacotron
- NEG
- Item2Vec
- Negative Sampling
- Tacotron2
- ANNOY
- BOJ
- Dilated convolution
- RecSys
- FastSpeech
- 추천시스템
- SGNS
- Skip-gram
- 백준
- ALS
- CV
- matrix factorization
- Collaborative Filtering
- Implicit feedback
- Recommender System
- word2vec
- TTS
- CF
- FastSpeech2
- 논문리뷰
- Today
- Total
devmoon
FastSpeech2: Fast and High-Quality End-to-End Text to Speech 본문
https://arxiv.org/abs/2006.04558
FastSpeech 2: Fast and High-Quality End-to-End Text to Speech
Non-autoregressive text to speech (TTS) models such as FastSpeech can synthesize speech significantly faster than previous autoregressive models with comparable quality. The training of FastSpeech model relies on an autoregressive teacher model for duratio
arxiv.org
한국어 음성합성 프로젝트를 진행하기 위해서 살펴본 TTS 논문들 중 이번에 적용시키고자한 모델인 FastSpeech2에 대해 살펴보았다. 사실 이전의 Tacotron 부터 시작해 Transformer TTS를 거쳐 FastSpeech까지 거친 것은 이번 논문 FastSpeech2와 음성합성 TTS분야의 발전과정을 알고싶었기 때문이었다. 한국어 음성합성의 경우 초성, 중성, 종성을 분리하고 발음 기호로 다시 작성해주는 별도의 과정을 필요로 하지만 모델 자체의 구조는 동일하게 가져갈 수 있을 것 같아 세세하게 들여다보기로 하였다.
1.Introduction
지난 게시글에서 보았던 FastSpeech는 Auto-regressive 모델들에 비해 비교적 빠른 속도로 음성합성을 진행한다는 장점을 가지고 있었다. FastSpeech는 각 음소를 얼마나 길게 발음해야하는지에 대한 duration predictor를 학습해야 했으며, duration predictor를 학습하기 위한 auto-regressive teacher 모델(Transformer TTS)와 `knowledge distillation`에 의존하고 있었다.
❓ Knowledge Distillation

Knowledge distillation은 부모와 자식모델 또는 선생과 학생모델을 두어 선생의 지식을 학생에게 주입하는 것을 말한다. 선생 모델은 더 복잡하고 규모가 큰 모델을 사용해 결과를 예측하고, 학생 모델은 동일한 입력을 받지만, 비교적 그 구조가 단순하고 규모가 작은 모델을 사용해 선생과 동일한 결과를 예측하도록 만든다. 이렇게 학습을 진행하면 더 적은 레이어만을 사용하여 선생의 복잡한 모델을 사용하지 않더라도 유사한 결과를 내도록 만들어줄 수 있다.
Teacher Model = Autoregressive Transformer TTS
Student Model = FastSpeech duration predictor
그러나 위와 같은 FastSpeech의 Teacher-student 구조는 모델의 학습 파이프라인을 더 복잡하게 만들어 시간을 많이 소비하게 된다는 단점이 존재하며, Teacher 모델이더라도 예측결과가 항상 정확하다는 보장이 없다. 따라서, FastSpeech에서 Teacher 모델을 통해 학습한 duration predictor가 예측한 값은 최종 mel-spectrogram을 예측하기 위한 정보가 부족한 information-gap 문제가 발생한다. 이를 해결하기 위해 FastSpeech2에서는 별도의 Teacher 모델을 사용하지 않고 실제 ground-truth를 계산해 모델을 학습시키기로 하였다.
또 다른 단점도 존재하는데 이는 FastSpeech만이 갖는 문제는 아니다. 음성의 경우 동일한 글자이더라도 어떻게 발음을 하는지에 따라서 다른 의미를 가질 수 있게 된다. 다시 말해, 하나의 텍스트가 여러 음성과 매핑될 수 있는 one-to-many mapping problem 이 발생한다. 이에 FastSpeech2 팀은 음성을 합성할 때 더 많은 정보들을 사용하여 다양한 소리를 낼 수 있도록 만들었다. 여기에는 좀 전에 살펴본 duration(FastSpeech보다 더 정확한), energy, pitch 라는 정보를 사용한다.
논문의 마지막에는 FastSpeech2 뿐만 아니라 FastSpeech2s를 소개한다. FastSpeech2s는 음성합성 과정 자체에 의문을 품으면서 고안된 모델 구조이다. 항상 음성합성을 할 때보면, acoustic model을 통해 mel-spectrogram을 생성하고 생성된 mel-spectrogram으로 부터 음성인 waveform을 생성해냈었다. FastSpeech2s는 중간의 mel-spectrogram을 직접 생성하지 않고 바로 waveform을 생성하여 FastSpeech2보다 학습속도를 3배 증가시킨 모델이다. 결과적으로 FastSpeech2와 FastSpeech2s모두 기존 FastSpeech보다 더 좋은 음성 합성 품질을 보여주었으며 이제부터 하나씩 살펴보고자 한다.
2. FastSpeech2 and 2s
2장에서는 논문에서 소개하는 모델인 FastSpeech2와 학습 속도를 개선시킨 FastSpeech2s를 설계할 때 어떤 부분에 유의했는지, 그리고 one-to-many problem에 대해 더 자세하게 다룬다. 2장의 마지막에는 FastSpeech2s에 대한 모델 설명을 하며 어떻게 학습속도를 증가시킬 수 있었는지에 대해 자세하게 설명한다.
2.1 Motivation
One-to-many problem은 앞서 말한 것 처럼 하나의 입력이 여러개의 출력과 대응될 수 있는 것을 말한다. TTS역시 One-to-many problem 중 하나이며 하나의 텍스트가 여러 개의 음성에 대응될 수 있는 것과 같다. 그렇기 때문에 동일한 텍스트이더라도 높낮이, 소리의 크기, 길이, 운율들을 잘 조절해서 읽어야만 하며, 모델이 이 정보들을 활용해 텍스트를 정확하게 읽어내야만 한다.
Non-autoregressive TTS인 FastSpeech에서는 외부 정보로 duration(길이)과 문장 자체인 텍스트 정보만을 활용해 음성합성을 진행했기에 다양한 음성을 예측하기가 힘들었다. 따라서 학습 데이터셋에 과적합된 목소리가 생성될 수 밖에 없었다. 또한, FastSpeech는 학습 파이프라인이 복잡하며 실제 mel-spectrogram으로 음성을 합성하기에는 정보가 부족하다는 문제가 있다. 정리하자면 아래와 같다.
- Non-autoregressive TTS는 입력으로 텍스트만 사용하기에 다양한 음성을 만들어낼 수 없다.
- FastSpeech가 그나마 개선했지만, 추가 정보로 duration만 사용했으며, 이마저 정확하지 않았다.
- 생성된 mel-spectrogram으로 음성을 합성하기에는 mel-spectrogram 자체가 내포한 정보가 부족하였다.
2.2 Model Overview
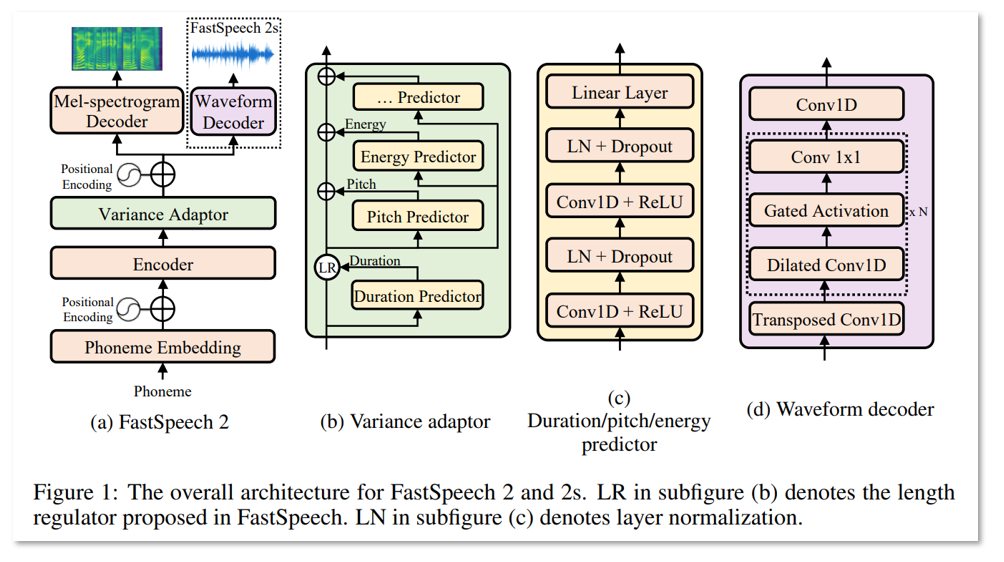
위 그림에서 (a)는 FastSpeech2의 전체구조를 간단하게 요약해서 보여준다. Figure1 (a)에서 보여주는 그림에 존재하는 모델의 컴포넌트들을 하나씩 살펴보자.
- `Phoneme Embedding`: 텍스트를 phoneme(음소)로 분리하고, 문자인 각 음소를 딥러닝에서 연산할 수 있도록 벡터형태로 임베딩해주는 블럭을 말한다.
- `Positional Encoding`: 임베딩 자체는 어떠한 위치적인 특징을 반영하고 있지 않기 때문에 임베딩끼리 순서가 뒤바뀌지 않도록 위치 정보를 삽입해준다.
- `Encoder`: Phoneme 임베딩 시퀀스를 Phoneme hidden 임베딩 시퀀스로 변환한다. (Feed Forward Transformer Block)
- `Variance Adaptor`: 음성합성할 때 추가 정보인 duration, pitch, energy를 phoneme hidden sequence에 더해준다.
- `Mel-spectrogram decoder`: hidden sequence로 부터 mel-spectrogram을 생성해준다. (Feed Forward Transformer Block)
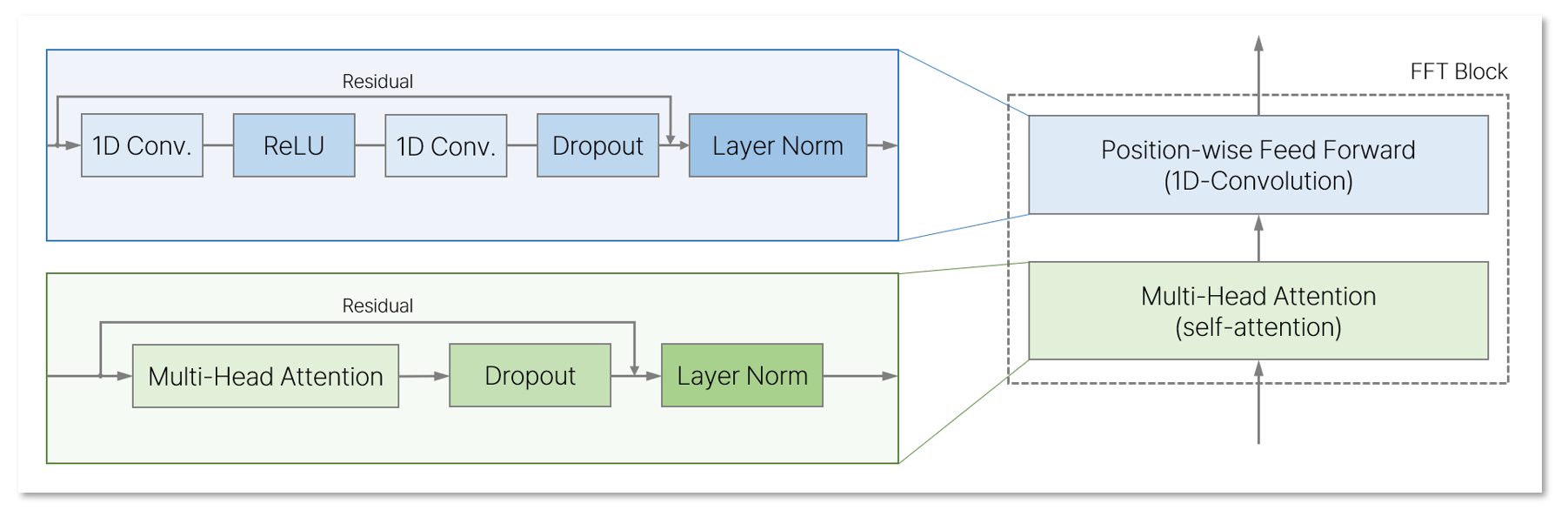
FastSpeech2의 Encoder와 Decoder는 모두 Feed Forward Transformer Block을 사용하였으며, 이는 self-attention과 1D-Convolution으로 이루어져있다.
FastSpeech2 자체만 보았을 때, FastSpeech와 꽤 유사한 모습을 보여주지만 몇 가지 차이점들이 존재한다. 먼저, FastSpeech에서 존재하던 Teacher-Student distillation 파이프라인을 제거하고, 직접 정답 mel-spectrogram을 사용하여 학습하였다. 덕분에 Teacher 모델이나 distillation과정에서 발생할 수 있는 정보의 손실(Information loss)를 피하고 음성품질을 향상시킬 수 있게 되었다. 두 번째로, FastSpeech에서는 duration predictor만 사용했던 것에 반해, FastSpeech2에서는 energy predictor와 pitch predictor를 두어 더 많은 음성학적 정보를 포함시키려고 하였다.
FastSpeech에서 duration predictor를 학습시키기 위해서는 autoregressive teacher 모델의 attention map으로 부터 추출한 값을 정답 duration으로 사용했었는데, FastSpeech2에서는 더 정확한 duration을 뽑아내기 위해 forced alignment로 얻어낸 duration 값을 사용하였다. 또한 energy와 pitch는 더 다양한 음성합성 결과를 보여줄 수 있어 TTS의 one-to-many mapping problem을 해결하는데 도움을 주었다고 한다.
2.3 Variance Adaptor
Variance Adaptor는 음성합성에 사용되는 추가정보를 phoneme hidden embedding sequence에 더해주는 연산을 한다. 앞서 계속 언급했듯이, Variance adaptor는 duration, energy, pitch를 사용한다고 했었다. Adaptor의 연산과정을 보기 전, 각각의 용어들이 음성에서 무엇을 가리키는지 먼저 살펴보았다.
- Duration: 음소(phoneme)을 얼마나 길게 발음해야하는가?
- Energy: 발음을 얼마나 세게해야하는가?
- Pitch: 음성의 톤 또는 목소리의 높낮이를 어떻게 해야하는가?
물론 3가지 정보 이외의 값들도 사용할 수 있다고 저자는 소개한다. 예를 들어, 감정과 관련된 직접적 정보, 화자의 말하기 스타일도 포함시키는 것도 가능하다. 하지만 일단은 3개의 특징에 대해서만 모델링하고 다른 값들은 future work로 남겨두었다. 이제 본론인 각 duration, energy, pitch를 어떤 모델구조로 예측할 수 있는지 살펴봐야한다. Predictor들을 모두 동일한 구조를 띈 모델로 학습하였기 때문에 아래에서는 1가지 구조만 소개한다. (Figure1 - (c))
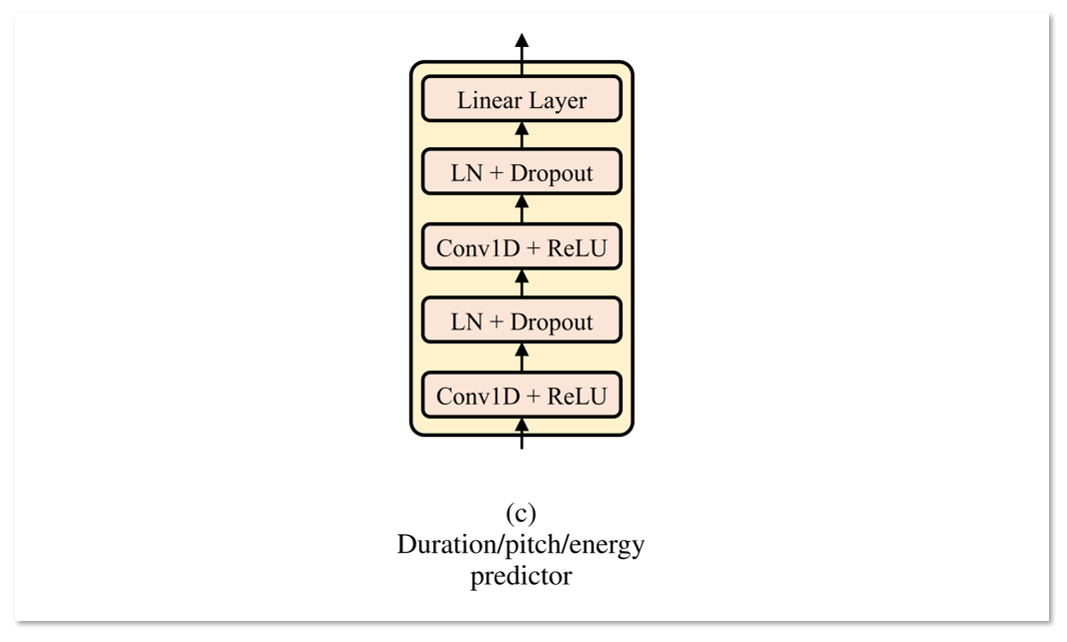
2.3.1 Duration Predictor
첫 입력으로 `Encoder`를 거친 phoneme hidden sequence를 받아 각 phoneme의 duration을 예측하는 부분이다. 각 phoneme이 몇 개의 mel-frame 동안 발화되어야 하는지를 결정하며 Mean Squared Error Loss로 학습하기에 적합하다고 한다. MSE Loss는 실제 duration과 예측 duration 값의 차이를 줄이도록 학습하게 된다.
그렇다면 정답 duration은 어디서 구할 수 있을까? 정답 duration은 FastSpeech에서는 autoregressive teacher 모델로부터 계산하였지만, 더 높은 정확도를 위해 FastSpeech2에서는 `Montreal Forced Alignment(MFA)`를 사용하였다. 저자는 MFA 방식의 도입으로 attention alignment의 정확도가 증진되었고, 모델의 입력과 출력사이에 존재하는 information gap을 줄이는데 기여하였다고 한다.
2.3.2 Pitch Predictor
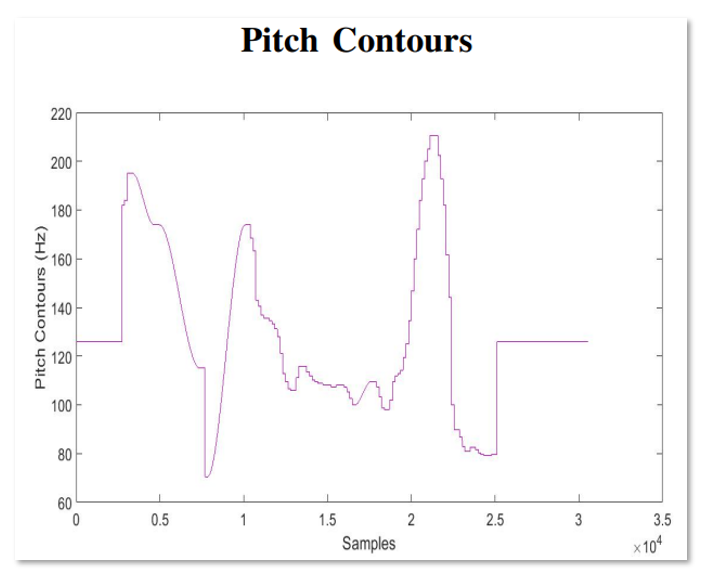
신경망을 기반으로한 TTS 모델들은 Pitch를 예측하기 위해서 오디오샘플의 Pitch contour(윤곽)을 그대로 사용했었다. Pitch Contour는 음성을 어떠한 음의 높낮이로 발음을 해야하는지 보여주는 그래프로 해석할 수 있으며 위의 보라색 선과같이 나타난다. Pitch Countour(Hz)가 높다는 것은 높은 음으로 발음되는 것을 말하며, 낮은 부분은 말을 하지 않거나 아주 낮은 목소리로 발음되는 것이다.
하지만 이런 실제 Ground-truth pitch contour를 사용하게 되면, 높은 변동폭으로 인해 예측한 pitch값이 실제 값과 오차가 크게 발생하는 원인이 된다. 따라서, 저자는 pitch의 예측성능을 높이기 위해서 ground-truth pitch contour를 그대로 사용하지 않고 continous wavelet transform (CWT)를 사용하여 pitch spectrogram으로 변형하여 사용하였다. 특히 CWT는 역변환 ICWT도 존재하기 때문에 pitch spectrogram을 다시 pitch contour로 돌려놓을 수 있어 inference 과정에서 사용된다. (학습할 때는 pitch spectrogram을 사용하며 MSE를 사용)
2.3.3 Energy Predictor
Energy는 음의 세기를 말한다. 이를 계산하기 위해 STFT의 amplitude에 L2 노름을 사용하였고, 각 프레임의 energy를 256개의 값으로 나누어주었다 (quantization). Pitch와 유사하게, hidden sequence에 energy embedding $e$를 더하여 음의 세기 정보까지 포함시킬 수 있게 만들었다. Energy predictor를 학습할 때는 quantizaed된 값이 아니라 원래의 값을 예측하도록 하였고, 실제 energy와의 MSE loss를 구하여 학습하도록 하였다.
아직 별도의 Vocoder를 필요로 하지 않고, mel-spectrogram의 생성도 필요없는 FastSpeech 2S에 대한 설명은 자세히 다루지 않았지만, FastSpeech와의 모델 구조는 큰차이가 없다고 생각된다. 2가지만 본다면, Knowledge distillation 대신 직접적인 target을 구한 것, 다른 하나는 duration predictor이외에 2가지(pitch, energy) 정보를 포함시킨 것 뿐이다. 그럼에도 현재 음성합성 모델들을 보았을 때, FastSpeech2 대비 큰 성능차이가 존재하지 않고 소폭 증가하는 양상만 보이기 때문에 그만큼 훌륭한 구조라고 생각이 든다.
'AI > 논문 리뷰' 카테고리의 다른 글
| Factorization Machines (3) | 2023.07.25 |
|---|---|
| FastSpeech: Fast, Robust and Controllable Text to Speech (4) | 2023.07.12 |
| Transformer TTS: Neural Speech Synthesis with Transformer Network (0) | 2023.07.06 |
| Tacotron2: Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions (1) | 2023.07.04 |
| WaveNet: A Generative Model For Raw Audio (0) | 2023.07.03 |



