
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- FastSpeech
- Noise Contrastive Estimation
- CF
- wavenet
- NEG
- matrix factorization
- Collaborative Filtering
- Implicit feedback
- 논문리뷰
- Tacotron
- CV
- 부스트캠프 AI Tech
- ALS
- Tacotron2
- 백준
- Recommender System
- Neural Collaborative Filtering
- ANNOY
- BOJ
- Negative Sampling
- Dilated convolution
- FastSpeech2
- Ai
- word2vec
- Skip-gram
- RecSys
- TTS
- SGNS
- Item2Vec
- 추천시스템
- Today
- Total
devmoon
Transformer TTS: Neural Speech Synthesis with Transformer Network 본문
Transformer TTS: Neural Speech Synthesis with Transformer Network
Orca0917 2023. 7. 6. 00:35https://arxiv.org/abs/1809.08895
Neural Speech Synthesis with Transformer Network
Although end-to-end neural text-to-speech (TTS) methods (such as Tacotron2) are proposed and achieve state-of-the-art performance, they still suffer from two problems: 1) low efficiency during training and inference; 2) hard to model long dependency using
arxiv.org
Abstract
End-to-End TTS를 지원하는 Tacotron2는 TTS분야에서 뛰어난 성능을 보여주었지만, 2가지 한계점을 가지고 있었다. 하나는 학습과 추론 단계에서 효율이 좋지 못해 시간이 오래 걸린다는 것, 다른 하나는 Encoder로 RNN을 사용하였기 때문에 과거의 정보들을 제대로 반영하지 못하는 long-range dependency 문제이다.
한편으로 신경망 번역 분야 (Neural Machine Translation, NMT)에서 아주 뛰어난 성능을 보여주며 기존의 RNN 기반 모델들의 성능을 모두 능가하는 `Transformer` 라는 모델이 등장하였다. Transformer 역시 encoder와 decoder구조로 이루어져 있기에 TransformerTTS의 저자는 Transformer 구조를 Tacotron2에 적용시키면 좋은 성능을 보일 것이라고 생각하였다. 저자들의 주요 개선점은 아래 2가지이다.
- Tacotron2의 attention (local-sensitive attention)을 Transformer의 multi-head attention으로 대체
- Transformer의 self-attention mechanism을 통해 long-range dependency 문제를 해결
입력 데이터로는 음소(Phoneme)을 사용하였으며, TransformerTTS를 사용하여 mel-spectrogram을 생성하고, mel-spectrogram을 음성으로 만들기 위해 vocoder 모델인 WaveNet을 사용하였다. 성능 평가지표로는 다른 것들과 마찬가지로 MOS를 사용하였으며, Tacotron2보다 0.048점 좋았으며 학습속도는 약 4.25배 빨랐다고 발표하였다.
1. Introduction
Transformer TTS를 살펴보기전, 기존에 존재하던 Tacotron과 Tacotron2 모델에 대해 알아볼 필요가 있다. Tacotron 계열 모델은 encoder와 decoder 구조로 구성되어 있으며 각 역할은 아래와 같다.
- Encoder: 단어 또는 음소(phoneme)을 입력으로 하여 encoder hidden state 생성
- Decoder: Encoder hidden state에 대해 attention mechanism을 적용시켜 mel-frame 생성
이때 눈여겨 봐야할 것은 Encoder와 Decoder모두 RNN계열 (LSTM, GRU)을 사용하였다는 것이다. RNN을 사용함으로써 발생되는 문제는 RNN은 현재의 입력과 이전 상태 정보를 반드시 필요로 하기 때문에 병렬처리가 불가능하다는 것이다. 병렬처리가 불가능하게 되면, 학습시간 또는 추론시간이 오래 걸리게 되는 문제가 발생한다. 동일한 이유로 long-range dependency 문제로 예측 값에 bias가 생길 수 있는 문제가 있다.
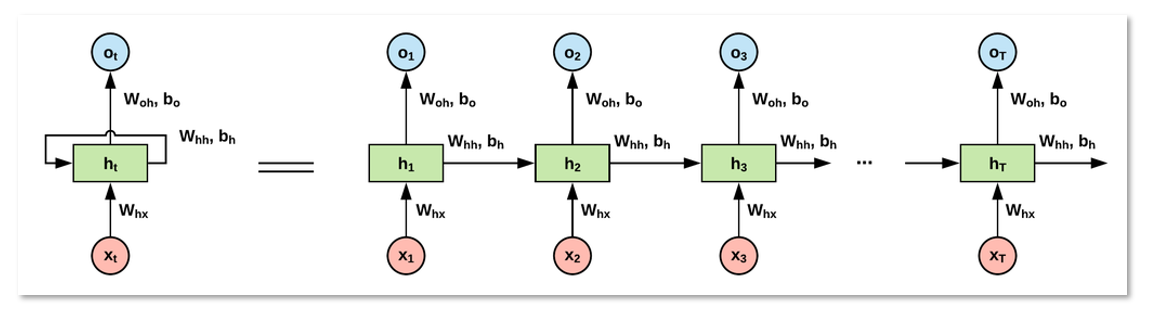
NMT분야에서는 위에서 언급한 2가지 문제를 해결하는 Transformer 모델이 발표되었다. TransformerTTS 저자는 해당 모델의 아이디어에서 영감을 받아 본 논문에는 Tacotron2의 장점과 Transformer의 장점을 결합한 새로운 end-to-end TTS 모델을 발표하였다. (Tacotron의 encoder, decoder구조를 Transformer의 multi-head attention으로 대체)

주요 장점으로 Transformer의 self-attention 덕분에 이전 상태 정보를 필요로 하던 의존성을 제거하여 학습을 병렬적으로 할 수 있게 되었다. 또한, self-attention mechanism덕분에 입력이 최단거리로 연결되기 때문에 long-range dependency 문제를 해결할 수 있었다. 마지막으로 TransformerTTS는 Transformer에서 사용된 multi-head attention 구조를 사용하여 여러 관점에서 attention을 구한 context vector를 생성할 수 있다는 장점도 존재한다.
2. Background
이번 파트에서는 먼저 sequence-to-sequence모델에 대한 간략한 소개 이후, TransformerTTS를 만들기 위한 준비물인 Tacotron2와 Transformer에 대해 살펴본다.
2.1 Sequence to Sequence Model
Sequence-to-Sequence model은 말그대로 sequnce를 입력으로 하여 출력도 sequence로 하는 모델을 말한다. 입력 sequence를 $(x_1, x_2, \dots, x_T)$ 라고 하고, 출력 sequence를 $(y_1, y_2, \dots, y_{T^\prime})$ 이라고 한다면, 출력 $y_t$는 이전의 모든 예측값 $(y_1, \dots, y_{t-1})$과 입력값 $x_t$에 의존적이어야 한다. 언어 번역 모델들이 seq2seq 모델이라고 볼 수 있으며 대부분의 경우, 입력 sequence의 길이 $T$와 출력 sequnce의 길이 $T^\prime$가 다르다. $(T \neq T^\prime)$

NMT를 예로 들자면 입력으로 영어, 출력은 한국어와 같은 sequence를 사용했다고 볼 수 있다. 그리고 sequence to sequence는 이전 예측값에 의존적이며 이를 조건부확률로 표현하면 $p(y_1, \dots, y_{T^\prime } \vert x_1, \dots, x_T)$ 가 된다.
$$ \begin{align} \tag{1} h_t &= encoder(h_{t-1}, x_t) \\ \tag{2} s_t &= decoder(s_{t-1}, y_{t-1}, c_t) \end{align} $$
- $h_t$ : timestep $t$에서 예측한 encoder hidden state
- $s_t$ : timestep $t$에서 예측한 decoder hidden state
- $y_t$ : timestep $t$에서 예측한 출력 token (단어)
- $c_t$ : attention mechanism에서 계산된 context vector
$$ \tag{3} c_t = attention(s_{t-1}, \mathbf{h}) $$
따라서 조건부확률은 확률들의 곱으로 풀어서 작성하면 다음 수식 (4)와 같다.
$$ p(y_1, \dots, y_{T^\prime} \vert x_1, \dots, x_T)=\prod_{t=1}^{T^\prime}p(y_t \vert \mathbf{y_{<t}}, \mathbf{x}) \tag{4} $$
$$ \tag{5} p(y_t \vert \mathbf{y_{<t}, x})=softmax(f(s_t)) $$
- $f(\cdot)$ : Fully connected layer

Attention mechanism에서 softmax를 사용하여 어떤 단어로 매칭될 것인지 출력 벡터를 확률로 변환하여 해석하는데, TTS는 이런 과정이 필요하지 않다. Decoder의 출력으로 나온 decode hidden state $\mathbf{s}$는 하나의 linear projection layer를 거쳐 spectrogram frame으로 변환된다.
2.2 Tacotron2

Tacotron2에 대한 설명은 Tacotron2설명 에서 확인할 수 있다. 간략하게 말하면 먼저 입력으로 음성으로 바꾸고자 하는 텍스트 sequence embedding을 사용한다. Sequence embedding은 3-layer CNN을 통과하여 long-term context를 추출한다. 추출된 long-term context는 RNN기반 Bi-LSTM 인코더에 입력으로 사용되고 attention 및 decoder로 전달된다.
Decoder에서는 attention의 결과로 2종류의 linear projection layer를 거친다.
- linear projection layer #1: mel-spectrogram 예측
- linear projection layer #2: stop token 예측
예측된 mel spectrogram은 5-layer CNN과 residual connection을 사용하여 한 번 정제되어 최종 출력으로 내보낸다. 해당 출력 값은 stop token이 등장하지 않아 다음 timestep이 존재한다면, 다음 timestep의 pre-net 입력으로 보내진다.
2.3 Transformer for NMT

Transformer는 recurrent connection과 convolution 연산을 모두 제거하고 오직 attention만 사용한 sequence-to-sequence 모델이다. Transformer는 NMT분야에서 RNN기반 모델들의 성능을 모두 능가하는 좋은 모델이며 다른 seq2seq 모델과 마찬가지로 encoder와 decoder 구조로 이루어져 있다.
Encoder는 다시 2개의 sub network로 구성된다. 하나는 multihead attention이며, 다른 하나는 feed forward network이다. Decoder 역시 Encoder와 유사하지만, Masked-multihead attention이 추가되어 있는 것이 차이점이다. Encoder와 Decoder모두 각 sub newtork에 residual connection과 layer normalization이 존재한다.
3. Neural TTS with Transformer

3.1 Text-to-Phoneme Converter
영어 발음은 open syllable과 close syllable에 따라 동일한 단어 또는 음절이라도 발음되는 방법이 다르다는 규칙이 존재한다. 물론 모델에서 이것을 학습하도록 하면 가장 좋지만, 가능한 모든 규칙을 파악하는 것과 적은 데이터 또는 부정확한 데이터가 입력으로 사용되었을 때 발생할 수 있는 문제가 많아, 텍스트(문장)를 발음이 나는 대로 적은 Phoneme을 기준으로 변환해 주었다. 바로 이 변환기를 `Text-to-Phoneme converter`라고 한다.
3.2 Scaled Positional Encoding
앞서 소개했듯 Transformer에는 recurrence나 convolution 연산이 존재하지 않는다. 그렇기 때문에 입력의 순서를 고려할 수 없게 되어 순서가 뒤바뀌더라도 항상 동일한 결과를 주게되는 문제가 존재한다. 따라서, Transformer에게 어떤 글자는 언제 발성을 해야 하는지의 정보인 `Triangle Positional Embedding`이 필요하다.
$$ \tag{6} PE(pos, 2i) = \sin(\frac{pos}{10000^{\frac{2i}{d_{model}}}}) $$
$$\tag{7} PE(pos, 2i + 1) = \cos(\frac{pos}{10000^{\frac{2i}{d_{model}}}}) $$
- $pos$: timestep
- $2i$: channel index
- $d_{model}$: 프레임 벡터의 크기
Transformer TTS에서의 attention은 source(query)와 target(key)의 도메인이 일치하지 않는다. NMT 분야의 Transformer는 key와 query모두 단어로 일치했다면, TTS 분야에서는 query는 텍스트가 되고, key는 mel spectrogram이다. 따라서 서로 다른 도메인을 갖기에 두 값에 서로 다른 positional encoding을 해줘야 하며 이를 학습가능한 가중치 $\alpha$를 사용하여 조절하도록 만들었다.
$$x_i = prenet(phoneme_i) + \alpha PE(i) \tag{8} $$
3.3 Encoder Pre-net

Pre-net은 Tacotron2에서 사용하던 것과 구조가 동일하다. 입력으로 텍스트 임베딩이 들어가는 것이 아니라 텍스트를 phoneme으로 변환한 값을 전달한다는 점에서 차이가 존재한다. 각 phoneme 임베딩은 512차원으로 구성되어 있고, convolution layer 역시 512차원으로 만들어져 있다. 3개의 Convolution이 쌓인 형태로 pre-net이 만들어졌으며, 마지막 ReLU 이후에는 linear projection layer를 두어 relu의 출력을 $[-1, 1]$ 사이 값으로 제한*하였다.
*triangle positional encoding 값이 $[-1, 1]$ 사이로 이루어져 있음
3.4 Decoder Pre-net

Transformer TTS의 출력인 mel-spectrogram은 2개의 Fully connected network와 ReLU활성함수로 구성된 `decoder pre-net`에서 사용되어 진다. Decoder pre-net에서는 입력인 mel-sepctrogram과 phoneme embedding을 동일한 공간으로 매핑하여 둘 사이의 유사도를 계산할 수 있게 만들어주는 역할을 한다. 둘 사이의 유사도를 계산할 수 있다는 것은 내적 연산으로 attetion 연산을 할 수 있음을 말한다. Pre-net 이후에는 center consistency 뿐만 아니라 traingle positional embedding과 동일한 차원을 맞춰주기 위해 Encoder pre-net처럼 linear projection layer를 두었다.
3.5 Encoder

Tacotron2에서는 encoder가 Bidirectional LSTM 으로 구성되어 있던 것에 반해, Transformer TTS는 Transformer의 encoder 구조를 그대로 사용하였다. Multi-head attention 덕분에 하나의 phoneme을 여러 관점에서 attention score를 계산하여 모델링할 수 있으며, 임의의 2개 프레임에 대해 long-range dependency해결을 해줄 수 있었다. 이 결과로 문장의 길이가 길어도 더 자연스러운 목소리를 들려주는 음성합성이 가능하게 되었으며, 학습속도 역시 빨라지게 되었다.
3.6 Decoder

Tacotron2의 decoder는 2-layer RNN과 attention으로 local-sensitive attention을 사용했었다. Transformer TTS deocder는 encoder와 마찬가지로 transformer의 decoder 구조를 사용하였으며, self-attention, multi-head attention을 사용하였다는 차이가 있다. 입력으로는 처음에 이전 step의 mel-spectrogram을 받아 decoder pre-net과 positional encoding을 거친다. 또 다른 입력으로는 multi-head attention에서 encoder의 출력을 사용한다. Multi-head attention 덕분에 encoder에서 만들어진 hidden state를 여러 관점에서 바라보고 통합할 수 있어 더 나은 context vector를 생성하는 것이 가능해졌다고 한다.
3.7 Mel Linear, Stop Linear and Post-net

Tacotron2와 마찬가지로 mel-spectrogram을 예측하기 위한 linear projection layer 1개와 음성 합성의 끝을 알리는 stop token을 예측하는 linear projection layer 1개를 두었다. 이전과 동일하게 post net에서는 5-layer CNN을 사용했다. 특히 stop token을 예측하는 layer에서 positive sample의 수가 매우 적은 불균형이 있었다. 이는 음성이 종료되지 않을 수 있는 문제를 발생시킬 수 있어 BCE loss를 계산할 때, 5.0~8.0 정도의 가중치를 더해주어 해결하였다고 발표하였다.
*참고자료
- Li, N., Liu, S., Liu, Y., Zhao, S., & Liu, M. (2019). Neural Speech Synthesis with Transformer Network. Proceedings of the AAAI Conference on Artificial Intelligence, 33(01), 6706-6713. https://doi.org/10.1609/aaai.v33i01.33016706
- Shen, Jonathan, et al. "Natural tts synthesis by conditioning wavenet on mel spectrogram predictions." 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2018.
- minjoon, [논문리뷰] Neural Speech Synthesis with Transformer Network (AAAI19), Tistory, 2022. 7. 8. https://music-audio-ai.tistory.com/30
- soobinseo, A Pytorch Implementation of "Neural Speech Synthesis with Transformer Network", GitHub, https://github.com/soobinseo/Transformer-TTS
'AI > 논문 리뷰' 카테고리의 다른 글
| FastSpeech2: Fast and High-Quality End-to-End Text to Speech (1) | 2023.07.19 |
|---|---|
| FastSpeech: Fast, Robust and Controllable Text to Speech (4) | 2023.07.12 |
| Tacotron2: Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions (1) | 2023.07.04 |
| WaveNet: A Generative Model For Raw Audio (0) | 2023.07.03 |
| NCF: Neural Collaborative Filtering (0) | 2023.02.11 |



