
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Skip-gram
- Ai
- NEG
- FastSpeech2
- Item2Vec
- wavenet
- 논문리뷰
- ANNOY
- Neural Collaborative Filtering
- BOJ
- word2vec
- Collaborative Filtering
- ALS
- Tacotron2
- matrix factorization
- Negative Sampling
- Dilated convolution
- RecSys
- CF
- SGNS
- TTS
- Recommender System
- Implicit feedback
- Noise Contrastive Estimation
- Tacotron
- CV
- 백준
- 추천시스템
- 부스트캠프 AI Tech
- FastSpeech
- Today
- Total
devmoon
연관 규칙 탐색 알고리즘 본문
이전 글에서는 찾아낸 연관 규칙 중에서 의미 있는 연관 규칙을 골라내는 2가지 방법에 대해서 살펴보았었다. 사실 어떤 것들이 좋은 것인지를 알아보기 전에 그 후보군을 만드는 것이 더 중요한 일이다. 아이템의 개수가 많아질수록 만들 수 있는 연관 규칙의 수는 절대적으로 수가 늘어나는데, 어떻게 모든 연관 규칙을 만들지 않고도 유의미하지 않은 것을 미리 걸러낼 수 있는지 알아보려고 한다.
연관 규칙을 탐색하는 알고리즘은 사실 연관 규칙 탐색에서 가장 중요하다고 할 수 있다. 실제로 그만큼 어렵고 해결하기 까다롭기 때문인데, 가장 naive 한 접근 방법(brute force)과 다음 3가지 연관 규칙 탐색 알고리즘이 존재한다.
- Apriori 알고리즘
- DHP(Direct Hashing & Pruning) 알고리즘
- FP-Growth 알고리즘
Brute Force Appoach

가장 기본적이고 단순한 방법으로는 가능한 모든 연관규칙을 탐색하여 minimum support와 minimum confidence를 만족시키는 연관 규칙만 후보군으로 올리는 방법이 있다. 당연히 모든 규칙을 탐색하기 때문에 높은 계산량으로 인한 많은 시간이 요구된다.
이를 시간복잡도로 계산하면 O(NMW)로 N은 Transaction의 수, W는 1개의 Transaction에 포함된 아이템의 수, M은 주어진 아이템들로 가능한 모든 부분집합의 수인 2d 가 된다. 이때, d 는 전체 Transaction에서 등장하는 고유한 아이템들의 수를 의미한다. 위의 시간 복잡도를 실제로 풀어서 계산량을 알아보면 3의 지수승으로 증가함을 알 수 있다.
R=d−1∑k=1[(dk)×d−k∑j=1(d−kj)]=3d=2d+1+1
다시 연관규칙을 탐색하기 위해서는 다음 2가지 방법을 거쳐야 했었다. 특히, 빈발 집합을 생성하는 과정이 훨씬 많은 시간을 요구하기 때문에 사람들은 minimum support를 만족시키는 Itemset을 생성하는 효율적인 알고리즘을 고안하였다.
- 빈발 집합 생성 (Frequent Itemset Generation) : Minimum support 이상의 모든 Itemset 생성
- 규칙 생성 (Rule Generation) : Minimum confidence 이상의 연관 규칙 생성
Apriori Algorithm
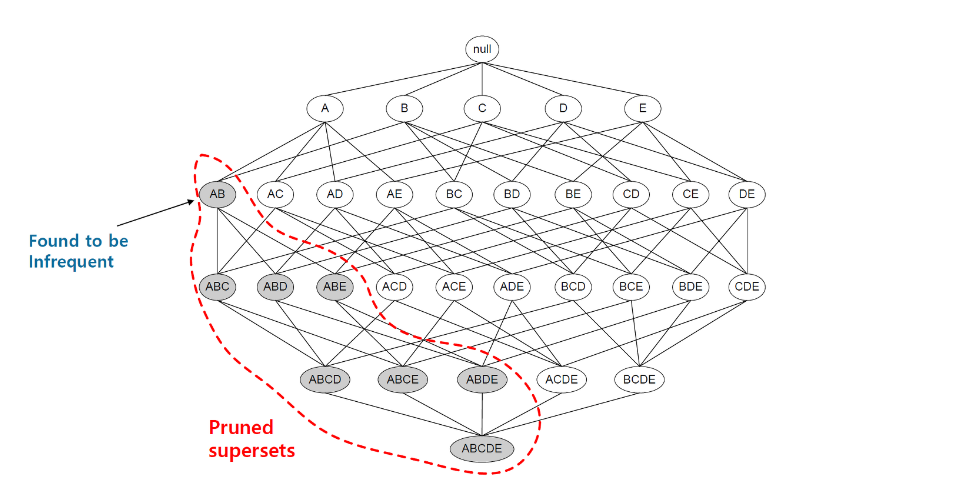
O(NMW) 에서 가장 문제가 되는 M 항의 크기를 낮춤으로서 최적화하는 방법이다. 더 정확히는 가능한 목록을 만들어나갈 때, 가지치기를 진행하여 탐색해야 하는 M의 수를 낮추는 것이다. 한 번 자세히 생각해보면, 어떤 Itemset X가 minimum support를 만족하는 빈발집합이라면, X의 모든 부분집합은 빈발 집합을 만족한다. 이 속성을 support의 anti monotone 속성이라고 한다.
∀X,Y:(X⊆Y)⇒support(X)≥support(Y)
반대로 보면, 빈발집합이 아닌 Itemset X가 있다면, X를 부분집합으로 갖는 모든 집합은 후보에서 제거되어도 된다는 것이며 이 과정을 pruning 과정이라고 부른다.
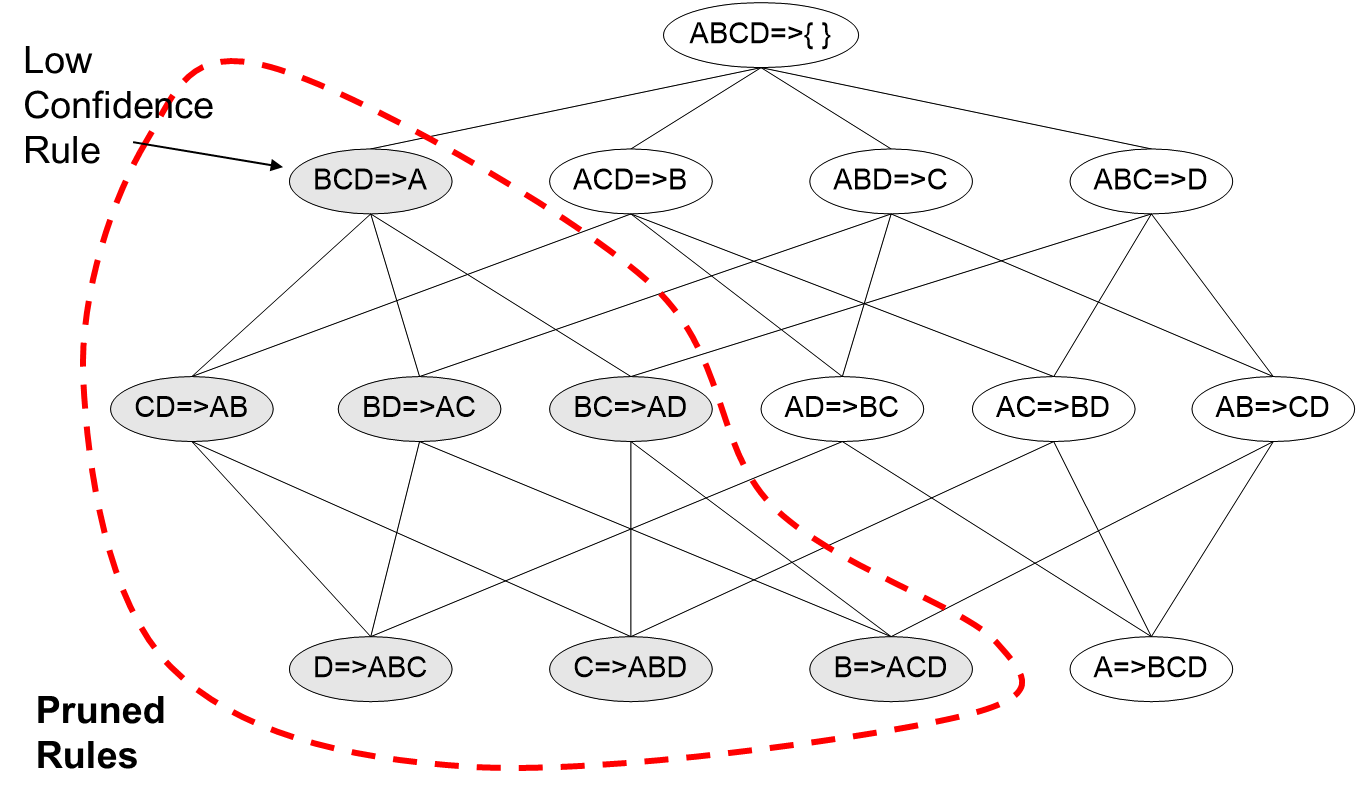
Apriori 알고리즘은 빈발 집합을 생성하는 과정(Frequent Itemset Generation) 이외에 규칙을 생성하는 과정(Rule Generation)에서도 적용될 수 있다. 빈발 집합 X와 X의 부분집합 Y에 대하여, confidence(Y→X−Y) 가 minimum confidence를 만족하지 못한다면, 그의 부분집합에 대해서도 마찬가지로 minimum confidence를 만족하지 못한다.
confidence(Y→X−Y)≥confidence(Y′→X−Y′)
- X : 빈발 집합
- Y : X 의 부분 집합
- Y′ : Y 의 부분 집합
DHP Algorithm
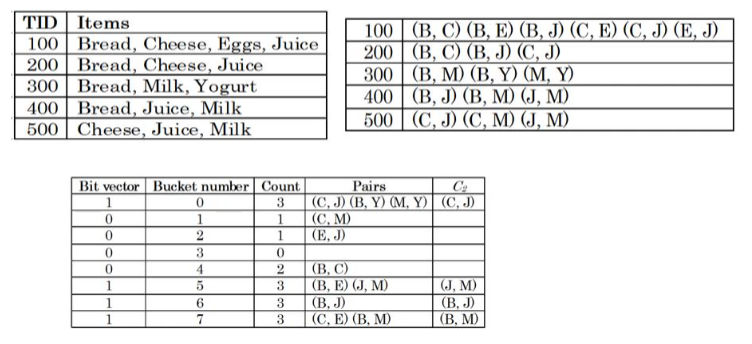
DHP 알고리즘은 Apriori 알고리즘의 성능을 개선시키기 위해 나온 알고리즘이다. DHP는 Direct Hashing & Pruning으로 Apriori 알고리즘의 Pruning에 Hashing을 적용했다고 볼 수 있다. Apriori 알고리즘에서는 각 단계마다 특정 Itemset이 몇 번 등장했는지 계산해야 하고, 여러 종류가 등장할 경우 저장할 공간의 크기가 커질 수 있는 문제가 생겼다. 하지만 DHP는 여기에 Hashing을 적용하여 차지하는 공간의 크기가 너무 커지는 것과 탐색에 시간이 오래 걸리는 것을 방지하였다.
하지만 DHP를 사용해도 해싱을 통해 나온 어떤 값에 minimum support 개 이상의 Itemset이 존재한다면, 다음 단계의 후보 Itemset으로 그 support count의 수가 가장 큰 Itemset을 올리는 것이다. 위에서 보여지는 예시를 예로 들자면, 먼저 각 Transaction에서 2개의 아이템으로 구성된 가능한 모든 Itemset을 검색한다.
| Transaction ID | Itemset |
| 100 | BC, BE, BJ, CE, CJ, EJ |
| 200 | BC, BJ, CJ |
| 300 | BM, BY, MY |
| 400 | BJ, BM, JM |
| 500 | CJ, CM, JM |
다음으로 각 Itemset이 전체 Transaction의 Itemset에서 몇 번 등장하게 되었는지를 확인하며, 각자리를 B(1), C(2), E(3), J(4), M(5), Y(6)로 변환하고 8로 나눈 나머지를 해시 함수로 사용한다. 해시 함수를 나온 값을 index로 하여 새로운 데이터베이스에 삽입한다. 예시에서 minimum support는 3이라고 가정한다.
- (예) CJ = 24, 24 % 8 = 0
| Bucket Number | Count | Itemset | Candidate2 |
| 0 | 5 | CJ(3), BY(1), MY(1) | CJ |
| 1 | 1 | CM(1) | |
| 2 | 1 | EJ(1) | |
| 3 | 0 | ||
| 4 | 2 | BC(2) | |
| 5 | 3 | BE(1), JM(2) | JM |
| 6 | 3 | BJ(3) | |
| 7 | 3 | CE(1), BM(2) | BM |
데이터베이스에 삽입된 Itemset들이 전체에서 몇 번 등장했는지 기록하고, 해당 Bucket의 등장 횟수가 minimum support 를 넘어선다면, 해당 bucket에 포함된 Itemset 중 가장 support count가 높은 Itemset을 다음 후보군으로 올린다. 이런 식으로 해싱을 하여 너무 많은 수의 Transaction을 검사하지 않아도 되도록 제한을 하는 것이다.
DHP 알고리즘은 해싱을 통해서 후보 집합에 대한 Itemset과 메모리의 사용량을 줄였지만, minimum support를 만족하는 아이템셋의 집합을 찾기 위해 데이터베이스를 스캔하는 횟수가 많아진다는 단점이 존재한다.
FP-Growth Algorithm
FP Growth 알고리즘에서 FP는 Frequent Pattern의 약자를 딴 것으로서 효율적인 자료구조를 사용하여 다음 후보 Itemset과 Transaction을 저장한다. 여기서 사용하는 자료구조는 FP 트리로서 frequent itemset들을 하나의 트리로 관리할 수 있게 해 준다.
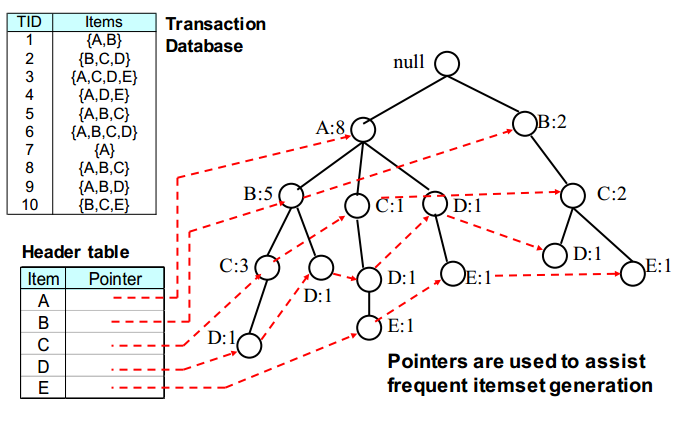
어떻게 보면, 트라이의 자료구조와 비슷하다고 볼 수 있다. 맨 위에서부터 Itemset을 하나씩 트리에 삽입하는데 트라이처럼 삽입한다. 이때, Itemset안의 Item의 순서는 support count가 높은 순으로 정렬되어 있어야 한다. 이렇게 FP Tree가 완성되면 각 Item에 대한 포인터는 위의 사진에서 빨간 점선과 같이 트리에서 동일 Item들을 가리키고 있게 된다.
이 FP Tree를 생성했을 때의 장점은 특정 Itemset에 대한 support count를 바로 알 수 있게 된다는 것이다. 예를 들어, ABC에 대한 support를 구하고 싶을 때는 가장 아이템들 중 가장 support count가 낮은 C가 ABC의 support가 된다. 결국 어떤 Itemset에 대한 support를 알고 싶어도 단 한 번의 tree 탐색으로 구할 수 있고 메모리의 절약도 된다는 장점이 존재한다.
'AI > 추천 시스템' 카테고리의 다른 글
| Neighborhood Based Collaborative Filtering (UBCF, IBCF) (0) | 2022.11.22 |
|---|---|
| Content Based Recommendation / TF-IDF (0) | 2022.11.02 |
| 연관 규칙 분석 / support, confidence, lift (0) | 2022.10.22 |
| 인기도 기반 추천 (조회 / 평점) (0) | 2022.10.20 |
| 추천시스템의 평가 지표와 Offline/Online Test 방법 (0) | 2022.10.20 |



