
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- Tacotron2
- Tacotron
- Collaborative Filtering
- Dilated convolution
- matrix factorization
- 백준
- Negative Sampling
- CF
- SGNS
- ALS
- TTS
- Skip-gram
- 추천시스템
- FastSpeech2
- BOJ
- CV
- Implicit feedback
- NEG
- word2vec
- Item2Vec
- wavenet
- ANNOY
- Neural Collaborative Filtering
- Noise Contrastive Estimation
- Recommender System
- RecSys
- 논문리뷰
- 부스트캠프 AI Tech
- Ai
- FastSpeech
- Today
- Total
devmoon
[논문 리뷰] VGGNet / Very Deep Convolutional Networks for large-scale image recognition 본문
[논문 리뷰] VGGNet / Very Deep Convolutional Networks for large-scale image recognition
Orca0917 2022. 10. 4. 20:00딥러닝의 레이어를 훨씬 깊게 쌓을 수 있게 영향을 준 이번 논문은 Computer Vision 분야의 대회였던 ILSVRC에서 2위를 차지한 VGGNet에 대한 논문이다. 레이어를 깊게 쌓을수록 파라미터의 수가 많아져 계산량이 늘어나고 시간이 오래 걸린다는 단점이 있었을 텐데, 이를 어떻게 극복했는지 신경 쓰면서 보면 좋은 논문이다.
Introduction
2015년 당시 고해상도의 이미지를 입력받아, 사물이나 물체를 인식하여 분류하는 대회인 ILSVRC에서 Convolution연산을 사용하는 딥러닝 모델(ConvNet)을 사용하는 팀들이 우수한 성적들을 많이 보여주고 있었다. 특히 Computer Vision 분야에서는 ConvNet은 마치 흙속의 진주와도 같았고 그렇기에 많은 사람들이 이를 개선하기 위한 시도들을 진행했었다.
저자는 특히 여러 시도 중에서 딥러닝 모델의 깊이에 집중을 하여 성능을 개선시키고자 했다. 결과적으로 VGGNet은 대회에서 사용하는 ImageNet 데이터셋뿐만 아니라 다른 대용량 데이터셋에 대해서도 SOTA에 준하는 성능을 보여주었다.
ConvNet Configurations
공정한 비교를 위해서 깊이를 제외한 다른 설정들은 고정시켰으며 아래에서는 더 자세한 모델의 구조와 설정값들에 대해서 기술한다. 모델의 여러 가지 버전들은 아래의 Discussion에 정리하여 비교분석을 진행하였다.
Architecture
학습과정에서는 입력으로 224 x 224 크기의 이미지가 입력으로 주어지며, 저자들이 사용한 유일한 전처리 방법은 각 이미지의 픽셀에서 평균 RGB 값을 빼주어 정규화를 시켜준 것 밖에 없다. 전처리를 거친 이미지는 여러 개의 Convolution 레이어를 거치게 되는데 이때 각 레이어에서는 다음 2가지 종류의 커널들만 사용하였다.
- 3 × 3 커널 : 상하좌우의 인접한 픽셀들을 인식하기 위한 최소 크기의 커널
- 1 × 1 커널 : 입력 채널에 대한 선형 변환으로 해석될 수 있음 (stride: 1)
Convolution Layer에서 Padding은 이전의 입력으로 들어온 이미지의 크기를 유지할 수 있을 만큼 설정하게 된다. Max Pooling은 2 × 2 크기와 stride 2로 연산된다. 이렇게 해서 convolution layer들이 완성이 되었으며 모델의 구조에 따라서 그 개수가 다르다. 이름은 레이어의 깊이에 따라 VGG16, VGG19와 같이 나뉘게 된다.
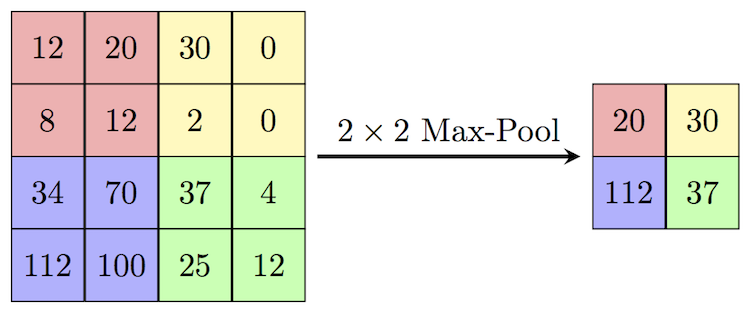
위에서 convolution layer를 모두 정의하고 쌓아 올렸다면, 이번에는 3개의 Fully Connected Layer가 등장한다. 처음 2개의 레이어는 4096개의 채널을 가지고 있으며 다음은 1000개의 채널로 이루어져 있다. 여기서 마지막에 1000개의 채널로 구성되는 것은 최종적으로 분류해야 할 클래스가 1000개이기 때문이다. 끝으로, 결과로 나온 1000개의 값에 대해서 softmax 연산을 진행한다.
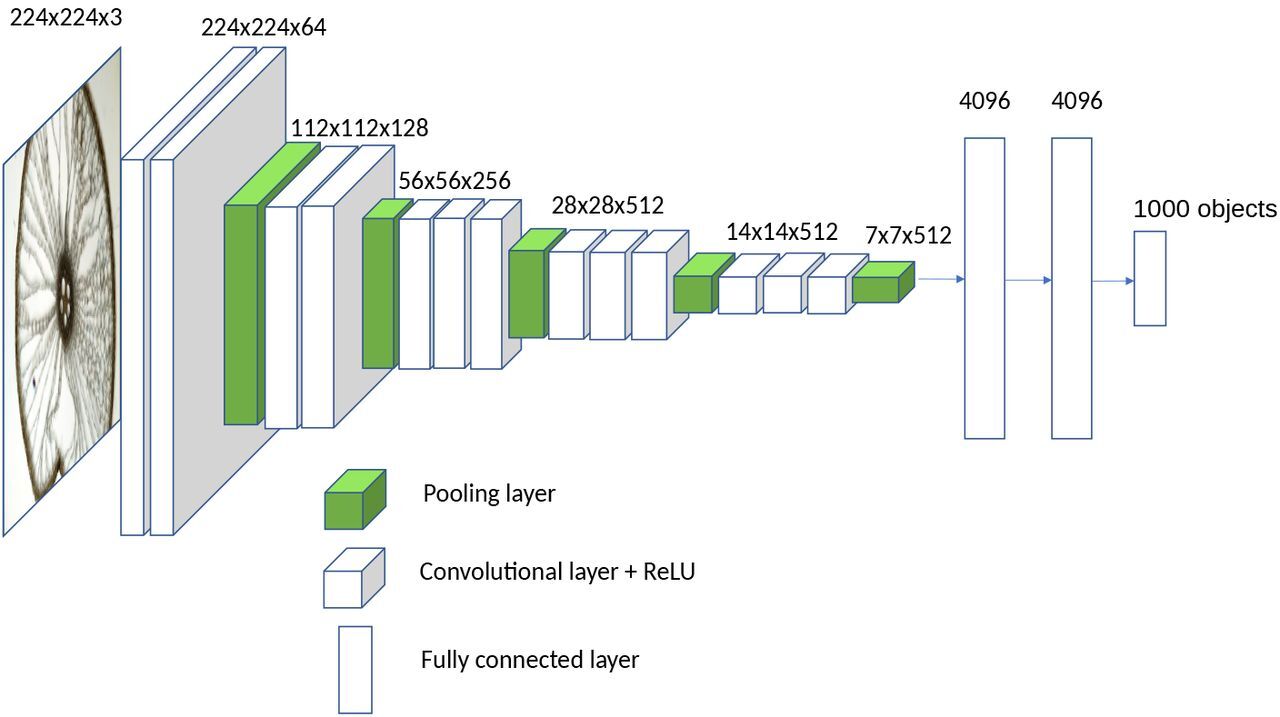
모든 hidden layer에 대해서 활성 함수로 ReLU를 사용했으며, LRN(Local Response Normalization, *AlexNet) 정규화 방법이 ImageNet 데이터셋에 대한 성능을 향상시키지 않았고 오히려 메모리 사용량의 증가와 계산시간의 증가만 초래했다고 밝혔다. 이는 전에 리뷰한 논문인 AlexNet과 상반되는 주장이다.
Configurations
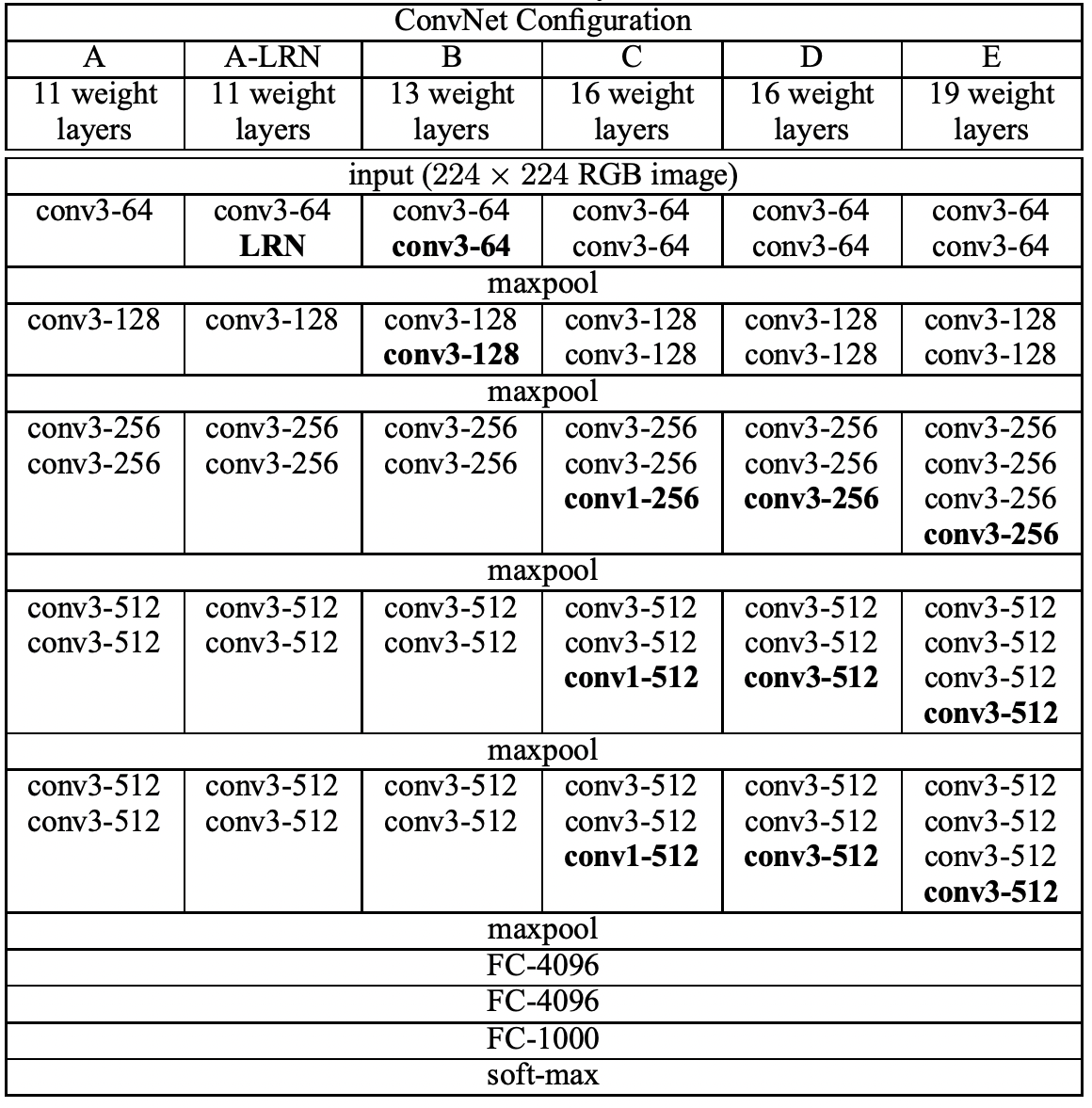
위에서 소개한 레이어의 더 상세할 설정값은 아래에 보이는 표와 같다. 저자들은 깊이와 레이어 설정에 따라서 모델을 6가지로 나누었으며 그 깊이는 11부터 19까지 있다. 특히 아래의 레이어를 보면 각 convolution 연산을 할 때 진행되는 커널의 채널 크기가 작은 것부터 시작되는 것을 알 수 가있다. 레이어를 지나면서 커널의 채널 크기는 512가 될 때까지 2배씩 증가시켰다. 아래의 표에서는 활성 함수인 ReLU를 간략화하기 위해 따로 표기해두지 않은 상태이다.
아래의 표는 각 모델마다 필요로 하는 파라미터의 크기이다. 모델의 깊이가 깊은데도 불구하고 사용되는 파라미터의 수는 더 얕은 모델의 파라미터보다 그 수가 더 작은 것을 알 수 있다. 이는 커널의 크기를 작게 잡았기에 가능하게 되었다.

Discussion
앞서 간단하게 말했지만, 저자가 주장하는 ConvNet은 독특한 특징이 있다. 바로 커널의 크기(Receptive Field)를 다른 모델들에 비해서 훨씬 적게 잡았다는 것이다. 다른 모델들은 11 × 11 크기나, 7 × 7 크기를 사용했었던 반면에 저자는 거의 최소 크기에 가까운 1 × 1이나 3 × 3을 사용하였다.
어떻게 보면 3 × 3 크기의 커널을 2번 연속 사용하는 것은 5 × 5 크기의 커널을 사용하는 것과 같고, 3 × 3 커널을 3번 연속 사용하는 것은 7 ×7 크기의 커널을 사용하는 것과 같다고 생각할 수 있다. 저자들은 이렇게 작은 크기의 커널을 굳이 쌓는 이유를 다음 2가지로 설명한다.
- decision function을 더 차별적이게 만든다.
- 파라미터의 수(크기)를 감소시킬 수 있다.
그렇다면 이제 1×1 크기의 커널은 왜 사용하는지 알아봐야 한다. 위에서는 단순히 입력 채널에 대한 선형 변환으로 생각할 수 있다고 했었다. 저자는 더 자세하게 인접한 Receptive Field에 영향을 주지 않으면서 비선형성을 증가시킬 수 있다고 말한다.
작은 크기의 커널을 사용하는 것은 VGGNet이 처음 시도한 것은 아니었다. 이전에 이미 시도했던 적이 있었지만, 여러 레이어를 쌓지 않았고, 대용량 데이터셋에 대해 학습을 시도하지도 않았었다. Goodfellow가 깊은 레이어를 사용하여 거리 번호를 인식하는 작업을 했었는데 좋은 성능을 보여주었다. 하지만 이들과의 차이점은 그 구조가 훨씬 복잡했고 feature map의 공간해상력이 좋지 못했다는 단점이 존재하였다.
Classification Framework
이전 장에서는 모델의 구조와 설정에 대해서 자세하게 다루었다면, 이번에는 학습을 하는 과정과 학습한 모델과 테스트 데이터셋을 이용해 평가를 한 과정에 대해서 소개한다.
Training
ConvNet을 학습하는 방법은 다양한 크기의 이미지에서 샘플링하는 방법을 제외하면 AlexNet(2012)을 학습한 방법과 동일하다.
- 다중 로지스틱 회귀 분석
- 미니 배치(256)
- momentum(0.9)
학습은 weight decay 방법을 사용하여 규제를 걸었으며, dropout은 초기 2개의 Fully Connected Layer에 적용하였다. 이때 사용된 dropout 비율은 0.5이며 학습률은 초기에 0.01로 설정되었다. validation 정확도가 증가하는 것을 멈추었다면 학습률에 0.1을 곱하여 감소시키도록 만들었다. 최종적으로 학습률은 3번 감소하였으며 74 Epoch 동안 학습을 진행하였다고 한다.
더 적은 수의 파라미터와 더 깊은 레이어가 있음에도 학습을 진행한 횟수가 적었다. 저자들은 어림짐작하길 깊은 레이어의 수와 작은 convolution 연산이 정규화와 같은 역할을 내포하고 있었을 것이며, 특정 레이어에 대한 초기화 덕분이라고 하였다.
각 네트워크에 대한 가중치 파라미터의 초기화가 중요한데, 논문의 저자는 위의 구조 중에서 가장 기본이 되는 A 형태 (11 layer)를 학습시키고, 이 학습된 가중치 파라미터를 다른 형태의 파라미터를 초기화하는 용도로 사용하였다. 모든 레이어에 다 적용시킨 것은 아니고 처음 4개의 Convolution 레이어와 마지막 3개의 Fully Connected Layer에만 초기화를 적용시켰다. 나머지 레이어에 대해서는 평균이 0이고, 분산이 0.01을 따르는 정규분포에서 랜덤한 수를 선택해 초기화를 진행한다. 저자들이 논문 발표 이후 말하기를 꼭 이미 학습된 파라미터로 초기화를 하는 과정 없이도, Gloro & Bengio의 random initialization procedure를 사용하면 된다고 하였다.

ConvNet의 입력으로 들어가게 되는 224 x 224 크기의 이미지를 얻기 위해서 주어진 training 이미지 데이터에서 random 하게 자르는 과정을 거쳤고, 데이터양을 늘리기 위해 좌우반전(horizontal flip)과 RGB 색상 값 이동의 기법을 사용하였다.
Testing
테스트 과정에서는 입력된 이미지가 학습된 ConvNet을 거치게 되는데 이때 입력 이미지는 한 번 처리과정을 거치게 된다. 입력 이미지에 대해 미리 정해둔 $Q$ 크기로 재설정하는데 이때 원래의 비율을 유지하도록 한다. 마찬가지로 학습과정에서도 크기를 재설정하는 과정이 있었는데, 학습할 때의 재설정 크기를 $S$라고 한다면 $Q$와 $S$는 같은 필요가 없다.

위에서 크기 조정을 마친 이미지는 딥러닝 레이어를 거치게 되는데, 위에서 보았던 마지막 3개의 Fully Connected Layer (FC Layer)는 Convolution Layer로 대체된다.
- 1번째 FC Layer : 7 x 7 Convolution Layer로 대체
- 2번째 FC Layer : 1 x 1 Convolution Layer로 대체
- 3번째 FC Layer : 1 x 1 Convolution Layer로 대체
모든 레이어를 거친 결과는 분류하고자 하는 클래스의 수와 같은 크기를 가진 채널이 될 것이며, 각 채널에 대해 속할 점수가 매겨져 있다. 마지막으로 클래스 점수에 대한 고정크기 벡터를 구하기 위해 방금 구해진 클래스 점수들이 sum pooling을 거친다. 입력 이미지에 대해서는 훈련과정과 마찬가지로 좌우반전을 통해서 augmentation을 진행했고, soft-max를 거친 결과에 대해 평균값을 구해 입력 이미지에 대한 최종 점수를 산출하였다.
테스트 과정에서는 모든 레이어가 Convolution 연산으로 바뀌었기 때문에 이를 Fully Convolutional Network라고 부르며, 하나의 이미지에서 여러 부분을 뽑아내서 augmentation 하는 과정이 불필요해졌다. 오히려 그 과정이 계산량을 증가시켜 비효율적으로 만들게 되었다.
Implementation Details
학습할 때, Multi-GPU 환경을 사용했으며 학습 데이터로 사용되는 각 이미지 배치를 GPU 들에게 나누어서 할당하는 환경을 말한다. 이렇게 각 GPU에서 계산을 통해 나온 그래디언트 값들은 평균을 구하여 전체 배치에 대한 그래디언트를 얻을 수 있도록 만들었다. 이렇게 각 GPU에서 계산하는 그래디언트 값은 동기화가 되어서 하나의 GPU를 사용하는 것과 동일한 결과를 내도록 만들어 주었다.
결과적으로 보았을 때, 하나의 GPU를 사용하는 것보다는 4개의 GPU를 사용하여 학습했을 때 완료되는 속도는 약 3,75배 더 향상되었다고 한다. 저자들이 사용한 NVIDIA Titan Black GPU를 사용했을 때는 네트워크를 학습시키기 위해 약 2~3주가 소모되었다.
딥러닝의 붐이 일어났다고 할 수 있는 AlexNet의 논문으로부터 이번에는 레이어를 더 깊게 쌓을 수 있도록 하는 엄청난 아이디어를 발표한 VGGNet에 대해서 살펴보았다. 딥러닝이 현재 이렇게 발전하기까지 Vision 분야에서 어떤 노력들이 있었는지 엿볼 수 있었고 Convolution 연산이 갖는 큰 장점을 결과로 보니 크게 와닿았다.
단순히 생각했을 때, 1x1 Convolution 연산은 절대 필요하지 않고 불필요한 연산일 것이라고 생각했었는데 그 필요성과 중요성에 대해서 다시 한번 생각해볼 수 있는 논문이었다. 논문에서 설명하는 더 다양한 실험들과 각각의 수치적 결과는 실제 논문을 참고해보면 좋을 것 같다.
'AI > 논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] Matrix Factorization techniques for Recommender Systems (0) | 2022.12.04 |
|---|---|
| [논문 리뷰] Collaborative Filtering for Implicit Feedback Datasets (0) | 2022.11.08 |
| [논문 리뷰] AlexNet / ImageNet Classification with Deep CNN (3) | 2022.08.25 |
| [논문 리뷰] Batch Normalization (2) | 2022.08.24 |
| [논문 리뷰] An overview of gradient descent optimization algorithms (2) | 2022.08.19 |



